企業の接客・案内業務をAIで代替するために、自然な音声対話が可能なAIアバターが求められた。課題は3つ:(1) 音声入力から応答開始までのレイテンシを人間の対話テンポに収めること、(2) 施設ごとに異なるナレッジとペルソナ(外見・口調・性格)を柔軟に切り替えられること、(3) ハルシネーションや不適切な応答を防ぐガードレールの実装。加えて、2Dイラストではなくフォトリアルなアバターによる対話体験が求められていた。
← WORKSリアルタイムAIアバター デモ: HeyGenアバター × RAG対話  ※画像はイメージです
※画像はイメージですReal-time Dialogue Pipeline: 音声入力からHeyGenアバター応答までの5ステージ 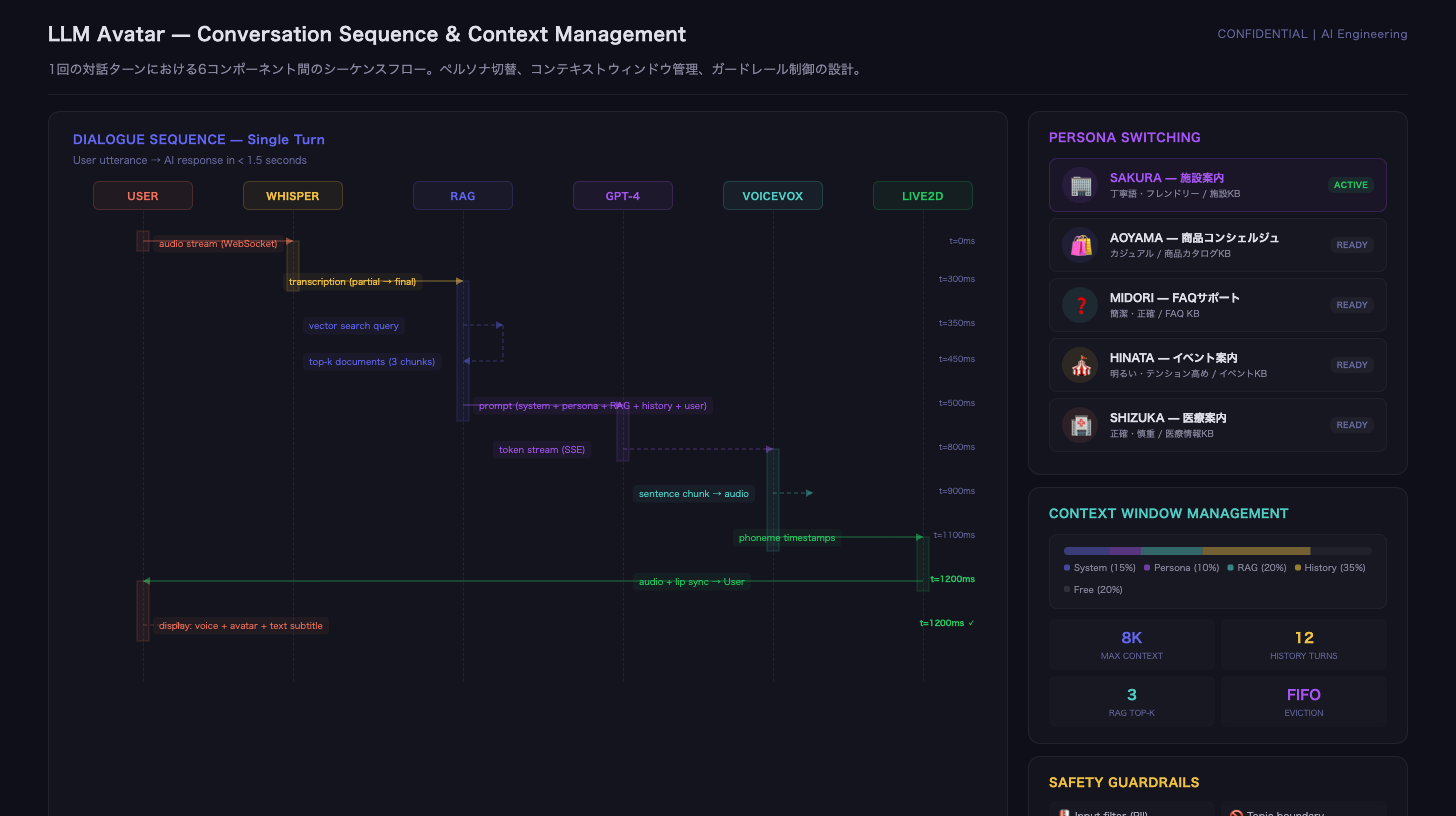 ※画像はイメージです
※画像はイメージですConversation Sequence: ペルソナ切替・コンテキスト管理・Safety設計
リアルタイムAIアバター — HeyGen × RAG対話システム
HeyGenのStreaming Avatar APIとRAG対話エンジンを組み合わせ、フォトリアルなAIアバターによる接客・案内システムを構築。Whisper STT → GPT-4 + RAG → HeyGen Streaming Avatarのパイプラインで、自然な音声対話を実現。
ROLE
AIエンジニア / テクニカルリード
TEAM
4名(AI 2名 + フロントエンド 1名 + PM 1名)
PERIOD
7ヶ月
主な成果
- 施設案内・商品説明・FAQの回答機能を持つフォトリアルなアバターを実装。回答難易度が高い質問に対しては有人エスカレーションにて対応。
- ユーザー満足度: 4.2 / 5.0(パイロット運用アンケート)
- 有人対応なし解決率: 78%
- HeyGen Streaming Avatar APIの採用により、TTS・アバター映像生成の自社インフラ構築が不要となり、フォトリアルなアバター表現と開発工数の削減を両立
TECHNOLOGIES
HeyGen Interactive AvatarGPT-4LangChainPineconeWhisperFastAPIWebSocketReactGCP
※画像はイメージです※画像はイメージです背景・課題
アプローチ
HeyGenのStreaming Avatar APIを中核に据えたリアルタイム対話パイプラインを設計。音声入力はWebRTC + VADで検知し、Whisper large-v3で日本語STT。テキストをPineconeでベクトル検索してRAGコンテキストを構築し、GPT-4でストリーミング応答を生成。生成テキストをチャンク単位でHeyGen Streaming Avatar APIに送信し、フォトリアルなアバターがリップシンク付きで応答する映像をリアルタイム配信する構成とした。LLMの応答生成とHeyGenの映像配信をストリーミング接続で並列化することでレイテンシを最小化。
HeyGenアバター(外見・声質)とシステムプロンプト(口調・制約事項・ナレッジベース参照先)の組み合わせでペルソナを構成。管理画面からNoCodeで切替可能とした。
ガードレールとして、入力フィルタ(PII検知)、トピック制限(対応範囲外は有人エスカレーション)、ハルシネーションチェック(RAG根拠に基づかない回答の検出と信頼度スコア付与)を実装。医療受付ペルソナは受付案内に限定し、診断・処方等は行わない設計とした(高リスク意図は有人エスカレーション)。