各部門がSalesforce、GA4、Zendesk、SAP、Firebase等を個別運用し、主要KPIの定義や集計ロジックが揃っていない状態。会議前後に数値突合で毎回数時間を要し、営業・マーケ・CSの顧客データが分断して、継続的なLTV(Lifetime Value)の分析や施策検証が回しづらかった。
← WORKS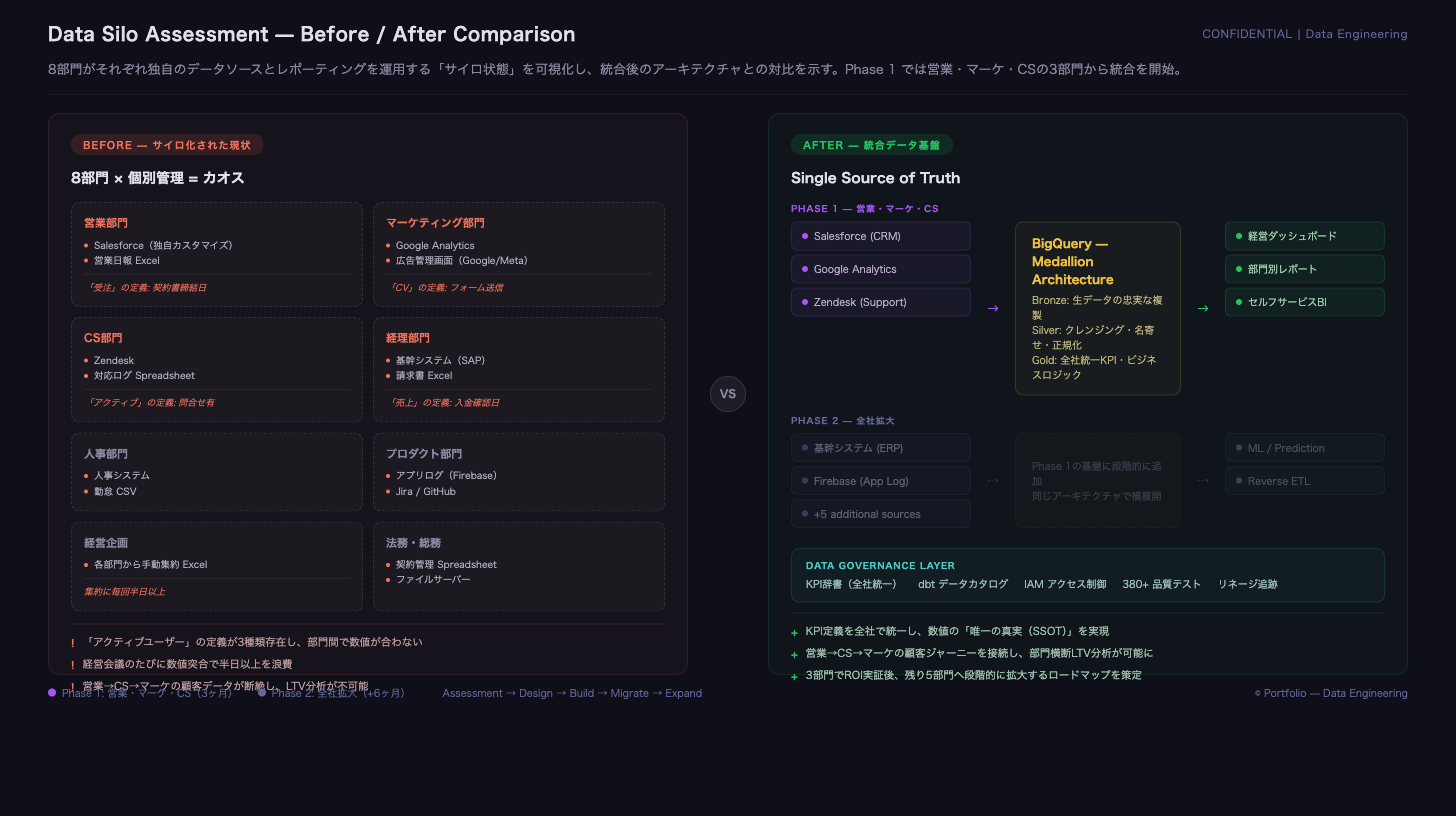 ※画像はイメージです
※画像はイメージですBefore/After: 8部門のサイロ状態から統合基盤へ  ※画像はイメージです
※画像はイメージですMedallion Architecture: 6レイヤー構成によるデータ品質保証 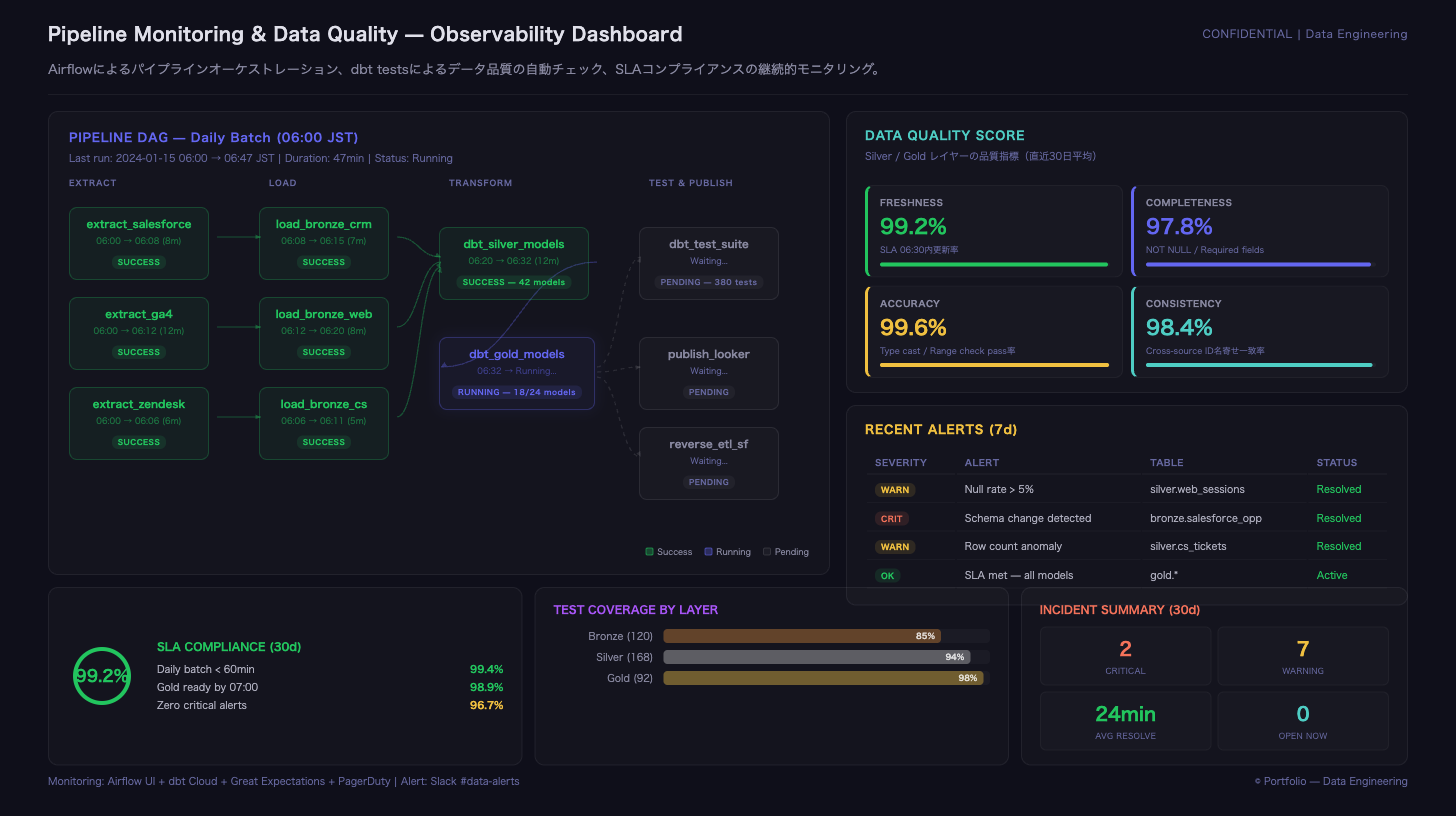 ※画像はイメージです
※画像はイメージですPipeline Monitoring: DAG実行監視とデータ品質ダッシュボード
データ基盤構築 — サイロ解消とMedallionアーキテクチャ
複数部門に散在するデータソースを、AWS上で段階導入の形で統合。まず営業・マーケ・カスタマーサポート(Customer Support: CS)の3部門をPhase 1として、共通KPIとレポート負荷の削減を実現し、他部門への拡大ロードマップを整備。
ROLE
データエンジニアリングリード / アーキテクト
TEAM
4名(Data Engineer 2名 + Analytics Engineer 1名 + PM 1名)
PERIOD
4ヶ月
主な成果
- 週次レポート作成工数: 10時間 → 3時間(-70%)
- Phase 1対象3部門で主要KPIの定義・算出根拠を統一し、用語辞書(ドラフト)を作成
- データ品質チェック: 80+ ルール(欠損・重複・型・参照整合・更新遅延など。ETL内チェック+SQL検証+監視アラート)
- Phase 1 → Phase 2: Phase 1で効果(工数削減・指標整合・可視化の定着)を定量確認し、Phase 2として追加3部門への拡大を決定。
TECHNOLOGIES
Amazon S3AWS GlueAWS AppFlowAmazon RedshiftAmazon QuickSightAmazon Managed Workflows for Apache Airflow(MWAA)AWS Identity and Access Management(IAM)Terraform
※画像はイメージです※画像はイメージです※画像はイメージです背景・課題
アプローチ
営業・マーケ・CSの3部門を対象に、利用中のデータソースと主要KPIの定義・算出根拠を棚卸しし、共通で使う指標を先に確定。次にAmazon S3上にBronze/Silver/Goldの置き場を分割し、AWS Identity and Access Management(IAM)(必要に応じてAWS Lake Formation)で部門境界と閲覧範囲を設計。データ取り込みはAWS AppFlowとAPI/バッチ連携で統一し、AWS Glueでクレンジング・結合・名寄せの範囲を段階的に実装、Goldでは共通KPIの集計テーブルと部門マートを整備。利用側はAmazon AthenaおよびAmazon Redshiftで参照できる形にし、Amazon QuickSightで週次の定例レポートを置き換え。あわせて重要テーブル中心に欠損・重複・型・参照整合などのチェックをETLに組み込み、Amazon CloudWatchで監視と通知、運用手順(更新時刻、障害時の一次対応、変更の流れ)を整備して、拡大に耐える運用の型を構築。