社内の規程・マニュアル・社内手続き・FAQについて、従業員が正確な情報にたどり着くまでに平均10分前後を要していた。人事・IT・総務・経理への問い合わせが月間1,200件に達し、回答する管理部門の工数が常態的に逼迫。既存の社内検索はキーワード一致が中心で、表現の揺れや言い換えに弱く、検索後に結果をクリックせず離脱する割合(検索放棄率)が35%に上っていた。
← WORKS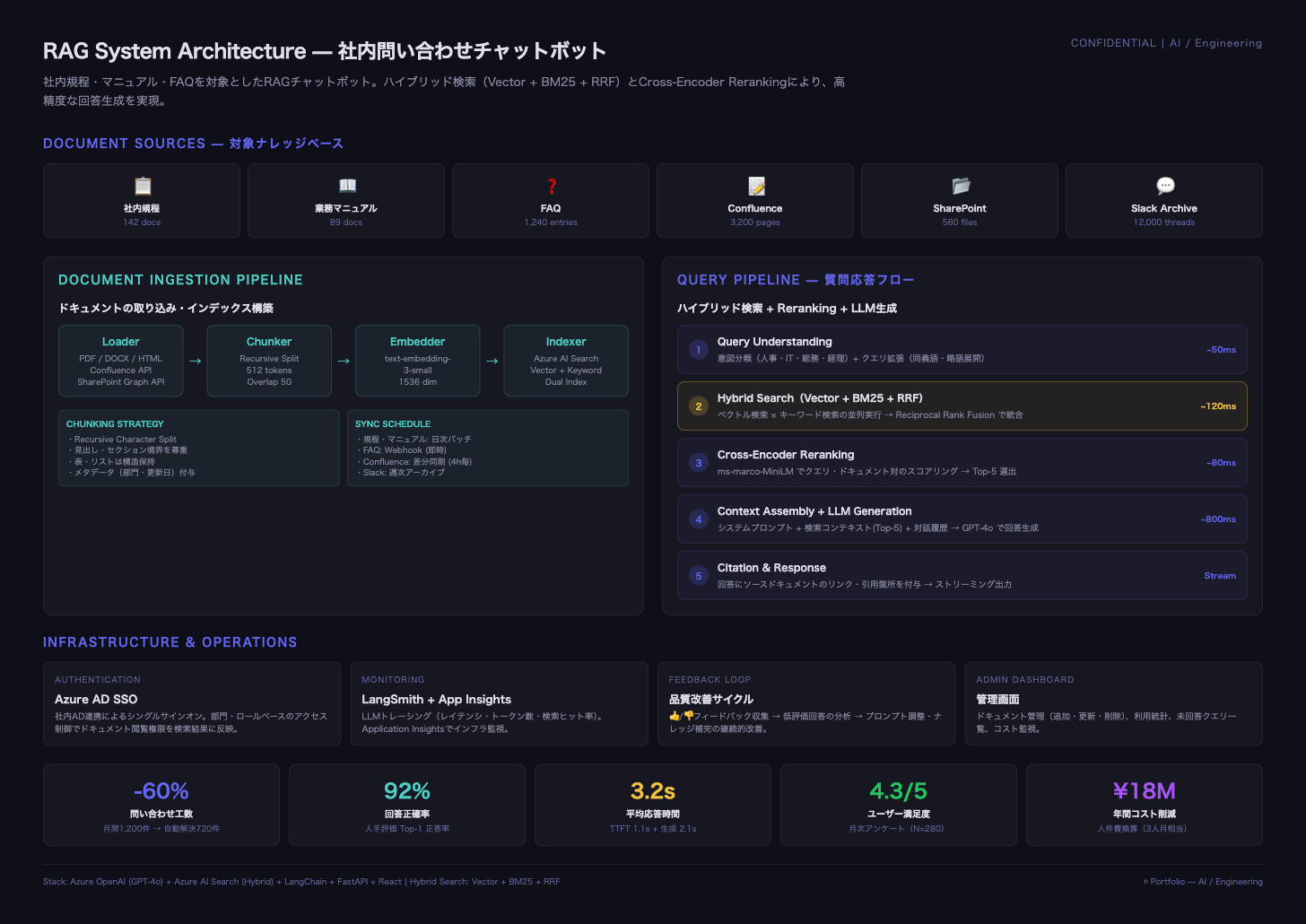 ※画像はイメージです
※画像はイメージですRAG Architecture: Document Ingestion + Hybrid Query Pipeline 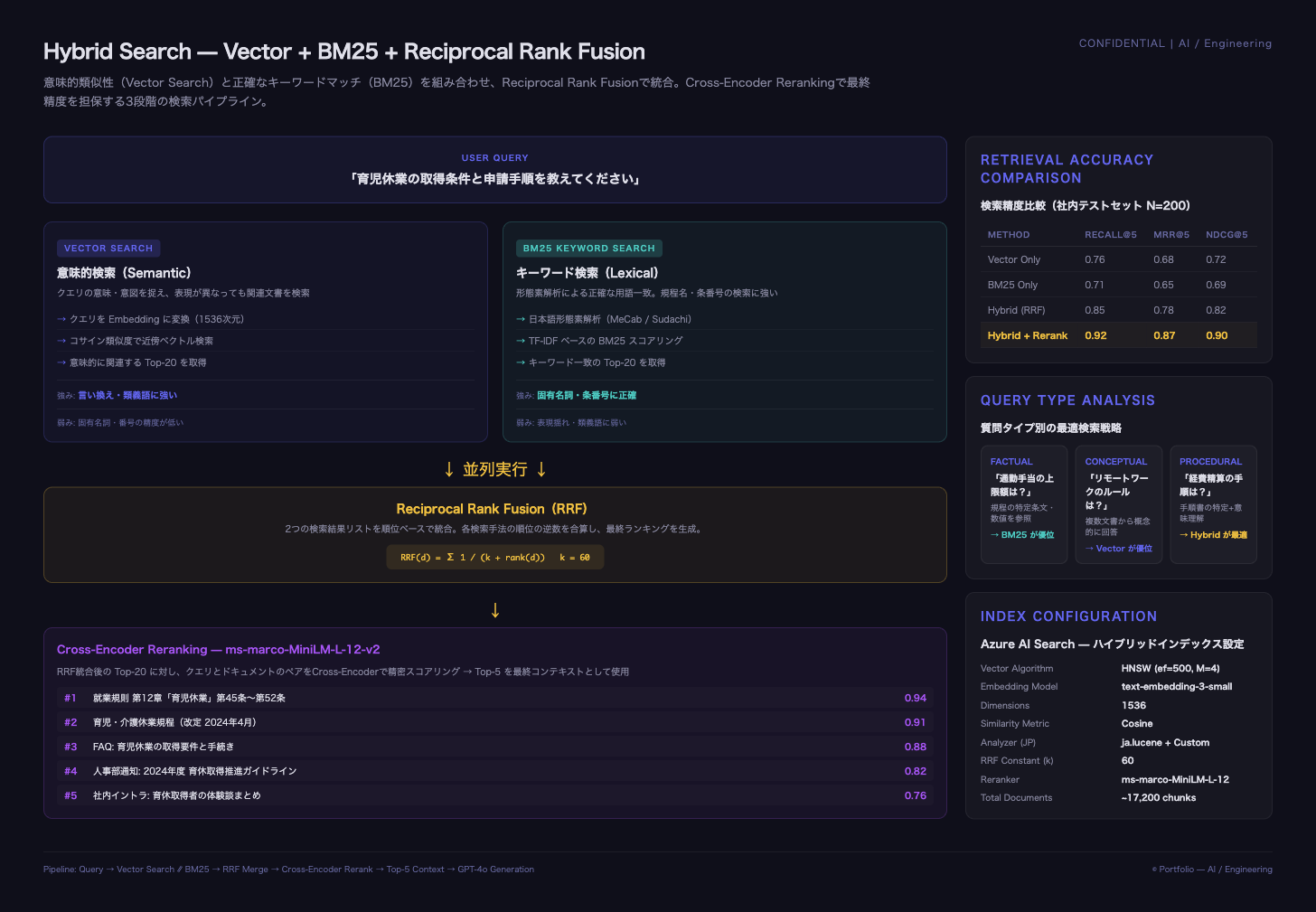 ※画像はイメージです
※画像はイメージですHybrid Search: Vector + BM25 + RRF + Cross-Encoder Reranking 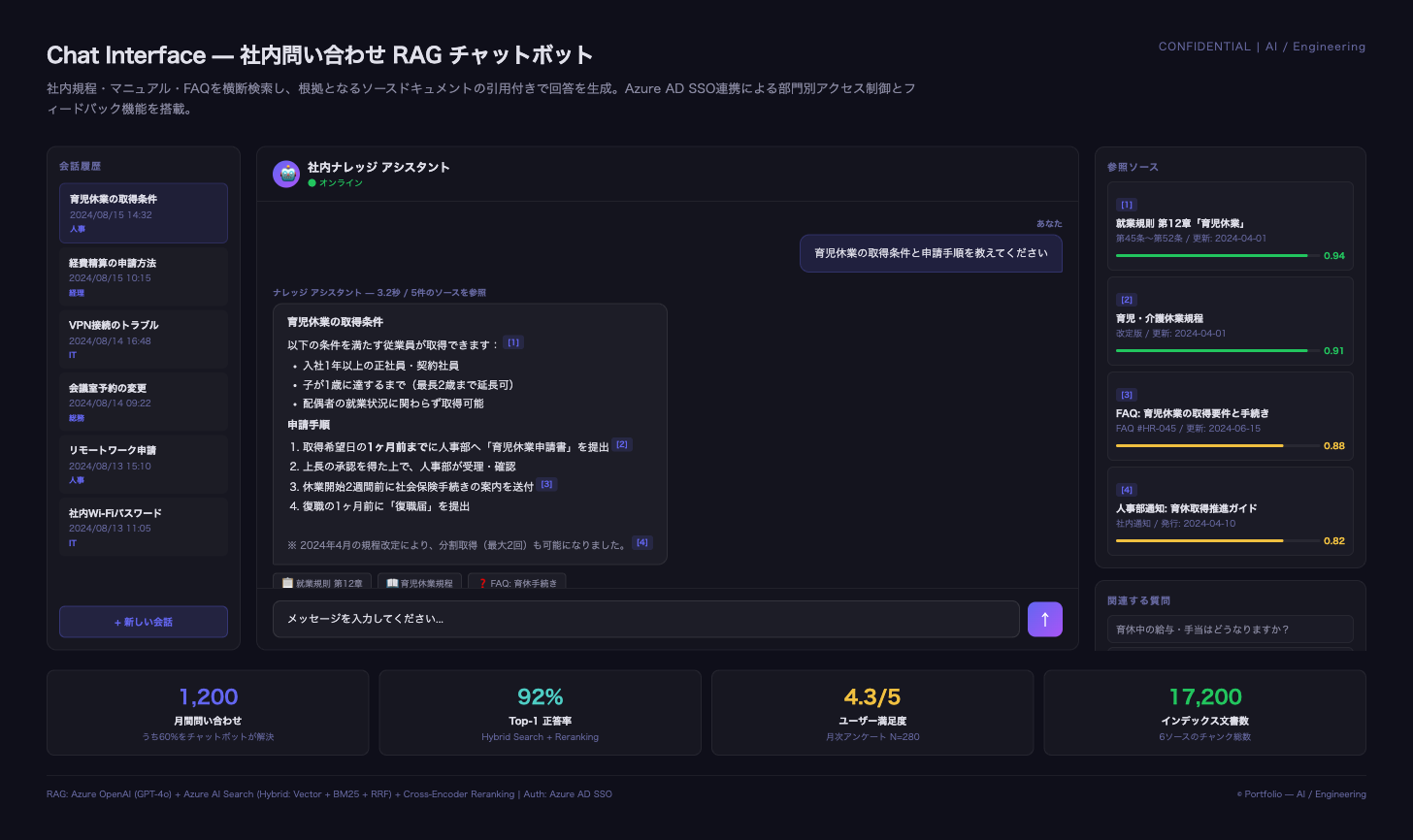 ※画像はイメージです
※画像はイメージですChat Interface: ソース引用付き回答 + 信頼度スコア + フィードバック
社内問い合わせRAGチャットボット — ハイブリッド検索基盤
社内規程・マニュアル・社内手続き・FAQ等のナレッジを横断検索するRAGチャットボットを構築。ベクトル検索(Semantic)とBM25キーワード検索を Reciprocal Rank Fusion で統合し、Cross-Encoder Rerankingで引用根拠の妥当率92%(検証用QAを人で評価)を達成。
ROLE
AIエンジニア / テクニカルリード
TEAM
3名(AI 1名 + バックエンド 1名 + PM 1名)
PERIOD
6ヶ月
主な成果
- 対象カテゴリ(定型の手続き・申請・FAQ)の問い合わせの60%(月間約480件)をチャットボットが自己解決し、管理部門の対応工数を削減
- 回答正確率(根拠文書の適合率 Top-3)92%を達成(代表質問200問で人手評価。Vector Only 76% → Hybrid + Rerank 92%)
- 平均応答時間4.0秒(TTFT 1.2s + 生成 2.8s)で実用的なレスポンスを実現
- ユーザー満足度 4.3 / 5.0(月次アンケート N=80)
- 年間コスト削減効果 約1,200万円(480件/月 × 平均対応15分の人件費換算、時給8,000円想定)
TECHNOLOGIES
Azure OpenAI (GPT-4o / Embeddings)Azure AI SearchLangChainCross-Encoder (multilingual)FastAPIReactPythonAzure ADLangSmith
※画像はイメージです※画像はイメージです※画像はイメージです背景・課題
アプローチ
Azure AI Searchのハイブリッド検索を活用し、ベクトル検索(意味の近さ)とBM25キーワード検索(用語一致)を並列実行、Reciprocal Rank Fusion(RRF)で統合する検索パイプラインを構築。さらに多言語対応のCross-Encoderでリランキングし、Top-5の高精度コンテキストをGPT-4o(モデルは変更可能)に渡して回答を生成する。
Document Ingestion Pipelineでは、6つのソースからドキュメントを取り込み、Recursive Character Splittingでチャンク化(512トークン、オーバーラップ50)。見出し・セクション境界を尊重し、部門・更新日などのメタデータを付与。Azure OpenAIのEmbeddingsモデルでベクトルに変換し、Azure AI Search上にベクトル検索とキーワード検索を併用できるインデックスを構築した。
日本語特有の課題として、形態素解析(Sudachi相当)によるBM25のトークナイズ調整、社内略語・固有名詞の同義語辞書によるクエリ拡張を実装。Microsoft Entra ID(旧Azure AD)SSO連携により、部門・ロールに応じたドキュメントのアクセス制御を検索結果に反映した。